
Scaling Memcache at Facebook

Memcached is a high performance, distributed in-memory caching solution. This paper talks about how Facebook adopted and improved Memcached to support world's largest social network.
1. Introduction
Social networking site like Facebook has to serve billions of request per second, support millions of concurrent user with real time communication and serve content on-the-fly. Memcached provides low latency access to shared cache pool at low cost.
2. Overview
Facebook consume more data than they create and this data spread across large variety of data source which requires a flexible caching strategy. Memcached provides a simple set of operations — set, get and delete — which makes it an attractive choice. Facebook took open-source version of memcached running with a single machine in-memory hash table and scaled it to support distributed store that can process billions of requests per second.
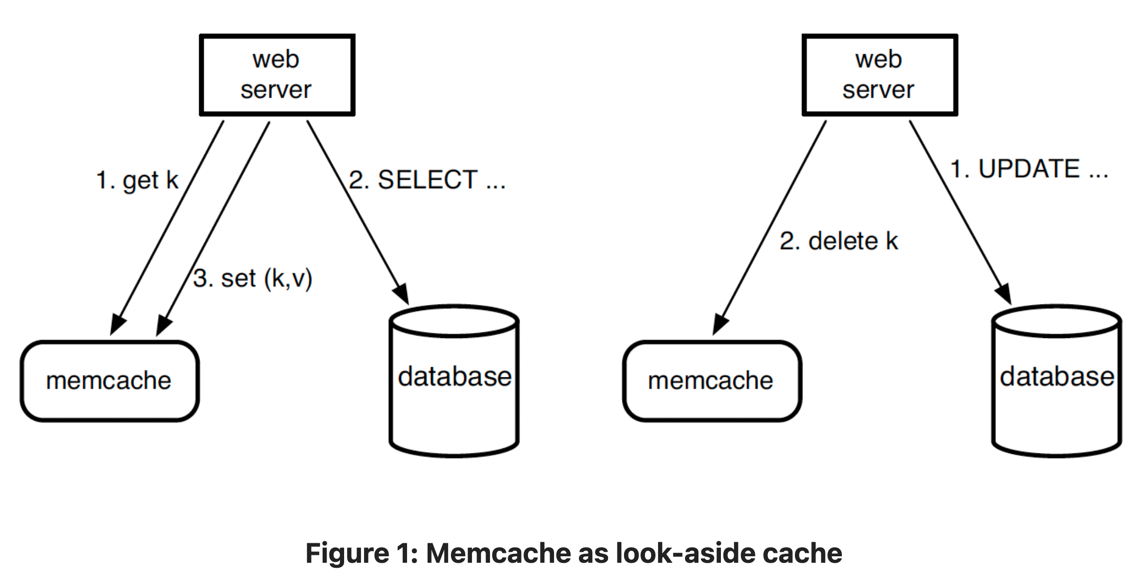
As shown in Figure 1, Facebook employees demand-filled look-aside caching strategy. When a web server needs data, it requests data from memcache, and if the item is not found in the memcache it fetches it from backend and populates cache. For write requests, it first makes changes to database and then sends a delete request instead of update in order avoid side effects.
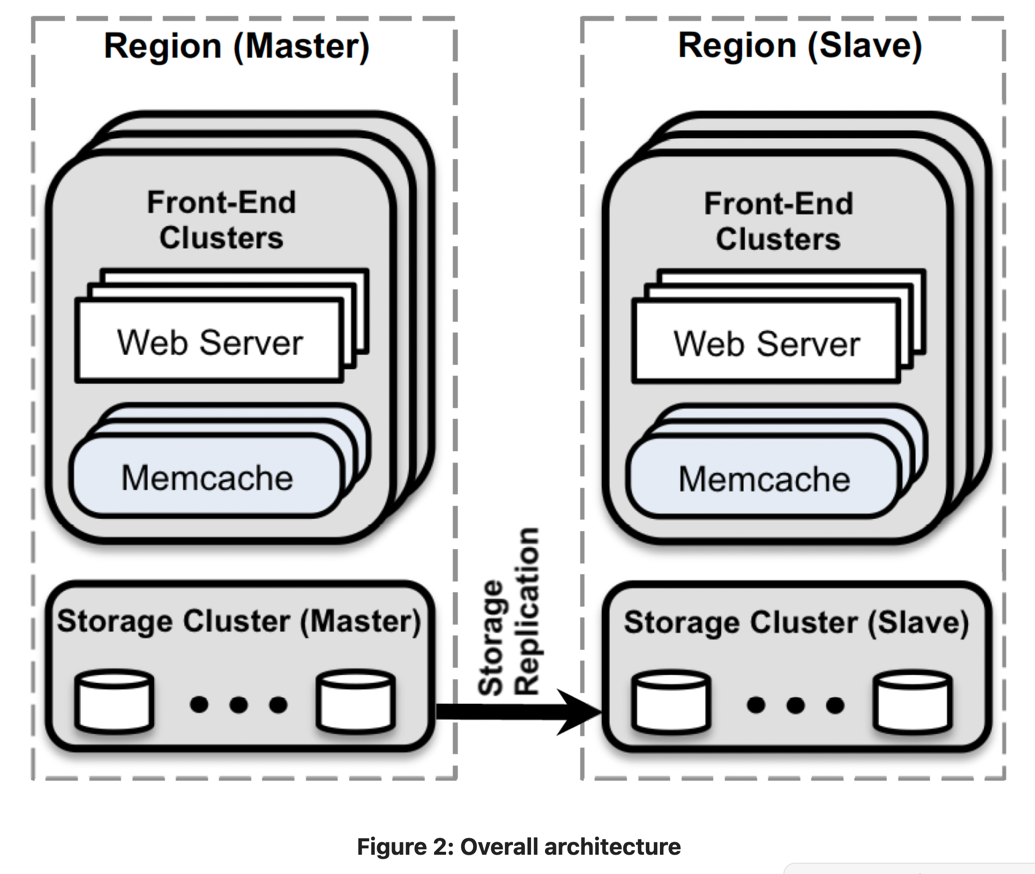
Figure 2 shows the Overall architecture of system, where front-end clusters are made up of web-servers and memcache instances. These front-end clusters together make up a Region and have a designated master region which keeps non-master regions up-to-date.
The paper emphasises themes that emerge at three deployment scales:
- Heavy workload on a cluster of servers
- Data replication between clusters
- Data consistency across multiple regions
3. In a Cluster: Latency and Load
Reducing Latency
To distribute the load hundreds of memcached servers are provisioned in each cluster with consistent item distribution. Each web-server also has a memcache client running which keeps track of all the memcached servers and provides communication interface.
Parallel Requests and Batching
In order to reduce network load clients build Directed Acyclic Graph representing dependencies between data to make concurrent request and batch requests. Memcached servers also don't communicate with each other instead the needed complexities are handled by stateless clients.
UDP for faster communication
Web servers bypass mcrouter for get requests and use UDP protocol as it is connection less and has less overhead. In contrast, set and delete require reliability and therefor use TCP connections via mcrouter.
Sliding Window
When client request a large number of keys, the responses can cause incast congestion and overwhelm hardware components such as racks and switches. Clients therefor use sliding window to control the outstanding requests. The window grows on successful request and shrinks when request fails.
Reducing Load
Leases and stale sets
Stale sets occur when a web server sets a value in memcache that does not reflect latest value, which can occur on concurrent updates to a key. While, a thundering herd happens when a key undergoes heavy read and write activity. As write invalidates cache, subsequent reads fail and fallback to persistent storage. A lease mechanism can solve both of these problems.
A memcache instance gives lease to a key on a cache miss via returning a token. This token is used to verify and determine whether data should be changed at the time of set. Token becomes invalid if a delete request for key is received. Further the rate at which tokens are generated for a key is regulated to mitigate thundering herd. If a request to read a key happens within 10 seconds of key generation, the requesting client is notified to retry in few seconds, and since the write takes only few milliseconds, the data is often available on the next try.
Pools
memcache is used by wide variety of systems with different requirements. Different workloads from different systems can cause negative interference resulting in decreased cache hits. To accommodate these differences, multiple cache pools are provisioned with a cluster — a general purpose wildcard pool, and separate pools for keys with special use cases. For e.g. a small pool can be provisioned for keys with frequent access for which cache miss is inexpensive and a large pool for keys with infrequent access but expensive cache misses.
Category of keys are also replicated between pools to improve performance when a key is accessed simultaneously by applications and load is more than what a single server manage.
Handling Failures
Unavailability of a memcached server can cause cascading failures to backend services due to excessive load. Small outages are usually handled by automated remediation system. But this process can take few minutes and can cause cascading failures. Thus a small set of machine named Gutters are dedicated, to take over the responsibility of failed servers. When a client does not receive a response to get request, it assumes the server is down and falls back to Gutter pools. If an entire cluster of memcache has to be taken offline, web requests are diverted to another cluster which removes all the load from that cluster.
4. In a Region: Replication
Blindly horizontally scaling memcached and web servers can cause highly requested items to be more popular and get replicated across clusters. This over replication can cause incast congestions. To alleviate this web and memcached servers together are split into multiple frontend regions. These clusters, along with storage cluster, are called region. The data is replicated across this regions instead of clusters to allow for fewer failure domains.
Regional Invalidations
When a web server modifies data in storage layer, it also sends invalidations to its cluster to reduce the amount of time for which stale data is present in cache.
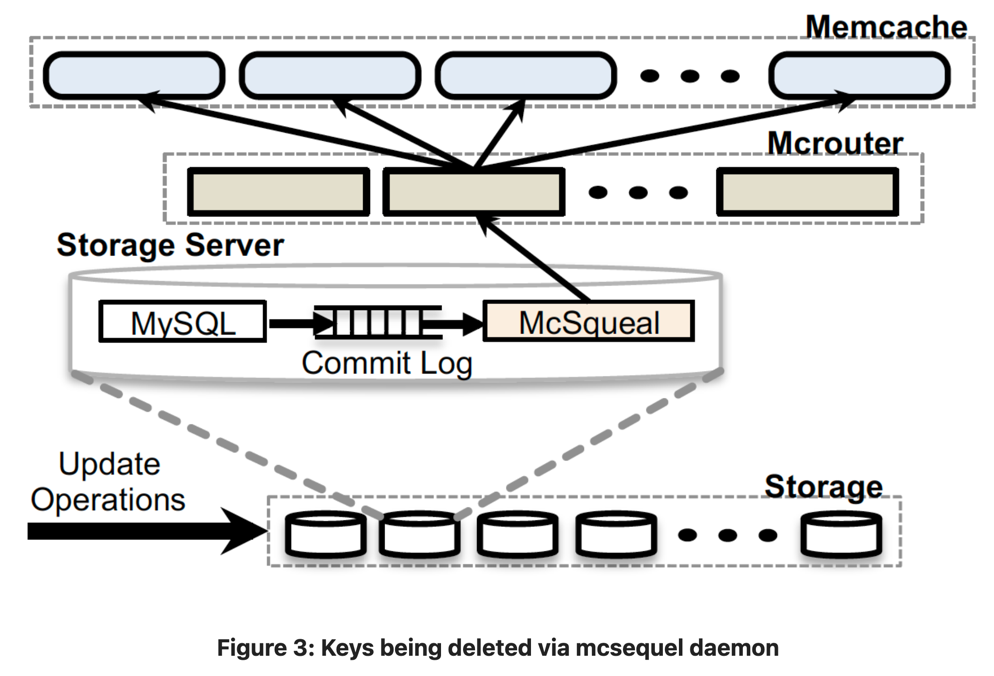
SQL statements that modify data also include memcache keys to be invalidated after transaction commits. Each database is equipped with an invalidation daemon named mcsquel, which examines SQL statements that database commits, extract any deletes, batches them to reduce network loads and at last sends them to a set of web servers running mcrouters instances in each frontend cluster. These mcrouters unpack individual deletes, and route these invalidation to the right memcached server co-located in that frontend cluster.
Regional Pools
Each cluster caches data based on user requests that are sent to it. If all requests are routed randomly, all the clusters have roughly same data cached which allows a single cluster to be taken down for maintenance, but can also cause unnecessary over-replication. To reduce replication, a set of frontend clusters can share the same set of memcached clusters called Regional Pool.
Crossing cluster boundaries for Regional Pool is expensive and incurs more network latency so it becomes important to decide which keys to be cached across clusters or have one single replica per region. Ideally only keys with infrequent access are migrated to regional pools as to reduce replication across clusters, while keys which are accessed frequently are cached at cluster level to reduce network latency.
Cold Cluster Warmup
When a new cluster is brought online, it has very poor hit rates diminishing its ability to insulate backend services. A system called Cold Cluster Warmup mitigates this by allowing clients in the cold cluster to retrieve data from warm cluster instead of persistent storage and put it in cold cache. This way cold clusters can be brought to full capacity in a few hours instead of days.
5. Across Regions: Consistency
When scaling across geographical regions, maintaining consistency between data in memcache and persistent storage becomes a challenge due to one single problem: replica databases may lag behind master database.
Requiring storage cluster to invalidate cache using mcsequel has consequences in multi-region architecture. Suppose, an invalidation arrives to non-master region before data has been replicated, this can cause caching stale data on subsequent reads. Similarly, when an update is made from non-master region when replication lag is large, the next user request can again result in reading of stale data being fetched and cached.
A remote marker mechanism is employed to minimise the probability of reading stale data. When a web server updates a data it sets a remote marker rk for a key k in the region, preforms write with k and rk to be invalidated in the SQL statement and deletes k in the local cluster. On a subsequent request for k, web server checks whether rk exists, and directs query to master or local region accordingly.
6. Single Server Improvements
The all-to-all communication pattern allows a single server to become a bottleneck for a cluster. A set of techniques are put in place in order to obviate these bottlenecks from happening.
Performance Optimizations
Facebook began with a single threaded memcached which used a fixed-size hash table. The first major optimizations were to:
- Allow auto expansion of hash-table for constant lookup times
- Make server multi threaded using global lock to protect multiple data structures
- Giving each thread its own UDP port to reduce contention on sending responses
Memory Management
Memcached employs a slab allocator to manage memory. The allocator divides memory into slab classes, each equipped with pre-allocated uniformly sized chinks of memory. An item is placed into smallest possible slab. When a slab runs out of free space it requests more memory in 1MB chunks. Once memcache runs out of free memory, storage for new items is done by evicting the LRU item within that slab class.
When workload changes, the slab class may no longer be enough resulting in poor hit rates. And adaptive slab allocator is implemented that periodically re-balances slab assignments based on currently items being evicted and if the next item to be evicted was used >20% more than average LRU items. If such a class is found, then the slab holding the LRU item is freed and transferred to needy class.
The Transient Item Cache
Memcached lazily evicts key based on their expiration time when serving a get request or when they reach end of LRU. This can allow short lived keys to waste memory until they reach end of LRU.
Further, a hybrid scheme is employed that allows lazy eviction of long-lived keys and proactive eviction of short-lived keys. Short lived items are put into a linked list (indexed by seconds until expiration) — called the Transient Item Cache — based on expiration time. Every second, all the items at the head of the list are evicted and head is advanced by one.
Software Upgrades
Memcached is modified to store its cached values and main data structures in System V shared memory regions so that the data can live across software upgrades and maintenance and there is no need for cold warmups.
7. Conclusion
Caches do not just keep the applications performant but they also prevent servers from outages. We saw how the memcached grew along with Facebook and its growing demand. The current state of memcache is a result of years of experimentations and research along with its live application on systems like Facebook. We can learn a few lessons from this paper:
- Keeping cache and persistent layer separate allows independently scaling them
- The system must allow gradual roll out and roll back of features
- System should be able to adapt to varying workloads and withstand outages
8. References
- Scaling Memcache at Facebook:
https://research.facebook.com/publications/scaling-memcache-at-facebook/